
In high school (~2012), I made a significant upgrade from my Nokia 1600 to an Android Jelly Bean device, API 16. I was fascinated by the apps available on the Play Store and became curious about creating my own. That’s when I discovered Adobe PhoneGap and ventured into HTML5 app development using jQuery Mobile. It was a thrilling and rewarding experience, culminating in the deployment of my first app on my Android device. This nostalgic period in high school marked my exploration into the world of app development and ignited a passion that I still carry with me today.
In the present day, 10 years after my high school experience, I find myself feeling a similar sense of awe and fascination when interacting with ChatGPT and other OpenAI APIs. The power and magic behind Language Models (LLMs) are truly transformative, much like the waves of innovation seen in Crypto and Web3. These LLMs have revolutionized the way we interact with applications.
If we reflect on the transition from the Web to Mobile, we witnessed a continuous cycle of improvement and iteration in Android and iOS APIs. It evolved from features like Actionbar and PullToRefresh to the sleek and intuitive Material UI, along with various other mobile APIs. This accelerated the adoption of a “Mobile first” strategy among businesses, as they sought to build and deploy mobile applications.
I firmly believe (I may be wrong, but What’s the downside?) that both the open-source LLMs and the upcoming versions and APIs from OpenAI and PaLM2 will have a transformative impact on the development of intelligent business applications. The possibilities are immense, and these advancements will further shape the way we build and leverage intelligent technologies. Google Search is experiencing disruption, and I must admit that about 7 out of 10 times, Bing or ChatGPT can provide me with precise answers to my queries, often rivaling the accuracy of StackOverflow. What’s more, ChatGPT even assists me in transforming the answers into formats such as JSON or XML, tailored to suit my specific needs. Additionally, Sourcegraph Cody proves to be a valuable tool for quickly delving deep into codebases and aids in bug fixing. The combined power of these alternatives is truly remarkable and is revolutionizing the way we approach search and code exploration.
Quick Overview
For this blog post, I’ll be using my Internet Bill from Bell and build a simple personal assistant using OpenAI API. The app will be able to answer specific questions like “What is the exact tax amount and percentage ?”.
Basics
There are three main components to this app: Generating Embeddings, Semantic Search and finally leveraging openAI Generative API to answer the questions. TLDR: refer the below diagram for the overview. Credits: Benny Cheung
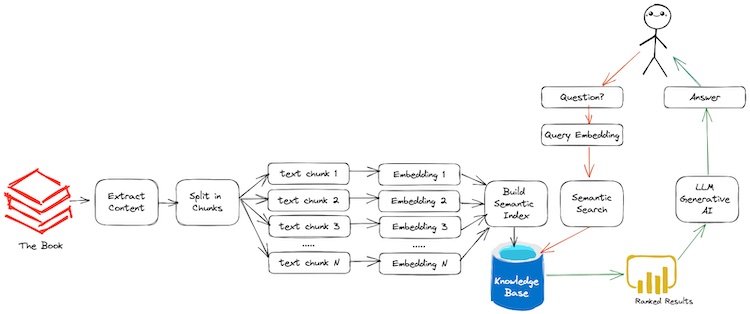
We’ll be using LangChain which is one of the powerful tool to communicate with LLMs, Load Documents, Indexing and Semantic Search. You can install the package using pip install langchain. However, it just acts like zapier for LLMs and you can build your own custom pipelines using langchain and openai APIs.
Generating Embeddings & Semantic Search
The first and foremost step is to load the pdf document using langchain and generate embeddings for each page. The corresponding page text are loaded and access with help of pages variable.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("bell_internet_expense.pdf")
pages = loader.load_and_split()
After loading the document, we’ll be using OpenAIEmbeddings to generate embeddings for each page. The OpenAIEmbeddings class is a wrapper around openai API and it helps in generating embeddings for each page. Additionally, FAISS is used to index the embeddings for faster retrieval and perform similarity search over the indexed embeddings.
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
faiss_index = FAISS.from_documents(pages, OpenAIEmbeddings())
docs = faiss_index.similarity_search("internet bill amount?", k=2)
for doc in docs:
print(str(doc.metadata["page"]) + ":", doc.page_content)
print("-----")
OpenAI Generative API 🪄
Finally the most exciting part, we’ll be using openai API to answer the questions. The OpenAI class is a wrapper around openai API and it helps in generating answers for the questions. Additionally, langchain helps in generating the context for the question and answer pair.
from langchain import PromptTemplate, OpenAI, LLMChain
template = """Context: {context} Question: {question}. Can you respond in json?"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
llm_chain = LLMChain(prompt=prompt, llm=OpenAI(temperature=0))
llm_chain.predict(context=docs[0].page_content, question="What's the exact tax amount and tax percentage? and whom it's billed to?")
The results which is yielded from semantic search is passed as Context ({context}) for questioning. However, It’s upto you to tweak the template and generate the context for the question and answer pair. Additionally, you should be aware about Prompt Injection attacks.
Results
The results are pretty accurate and it’s able to answer the questions with high accuracy. Here is the sample output from the above code snippet. Yes, Ontario has 13% tax rate (Federal + Provincial) and the exact tax amount is 7.15.
Answer: The exact tax amount is 7.15 and the tax percentage is 13%. The taxes are billed to the account owner, MR SHIVASURYA REDACTED_LASTNAME.
JSON Response:
{\n "tax_amount": 7.15,\n "tax_percentage": 13,\n "billed_to": "MR SHIVASURYA REDACTED_LASTNAME"\n}'
I have published this whole code snippets as Jupyter Notebook in Github. You can play around with the code and generate your own personal assistant. Additionally, you can also use langchain to build your own custom pipelines and leverage openai API to build your own personal assistant.
Source and Reference:
- Ask a Book Questions with LangChain and OpenAI: Blog
- Prompt Injection
- Example Notebook
Closing Note:
I hope this post is helpful for Langchain & LLM enthusiastic like me. For bugs,hugs & discussion, DM in Twitter. Opinions are my own and not the views of my employer.
